计算机性能和两个因素有关:响应时间和吞吐率。吞吐量和硬件有关,通过堆硬件就可以提高,重点还是响应时间
响应时间 = 指令数 * 指令执行的周期数(CPI) * CPU时钟周期时间
- 指令数和代码质量有关,垃圾代码往往生成的指令会有很多冗余
- CPI是指令执行的周期数,现代CPU可以通过流水线等技术优化cpu cycle
- CPU时钟周期时间是CPU主频决定的,主频越大,执行时间越短
cpu内部有一个晶体振荡器(简称晶振),每一次滴答就是一个时钟周期时间,计算方式为1/频率,比如cpu为2.8G hz,那周期时间就是1/2.8G,频率越大,cpu工作越快。
程序运行的时间统计
最常用的是计算时间差:程序结束的时间点-程序开始的时间点,这种时间称为wall clock time或者Ellapsed time。
这种计算方式有误差,比如在linux上计算wall clock time:
1 | root@hwsrv-998587:~# time seq 100000 | wc -l |
程序真正执行的时长是user+sys,很明显比real小,因为cpu不停地在不同的程序间切换,所以程序的执行时间会偏大
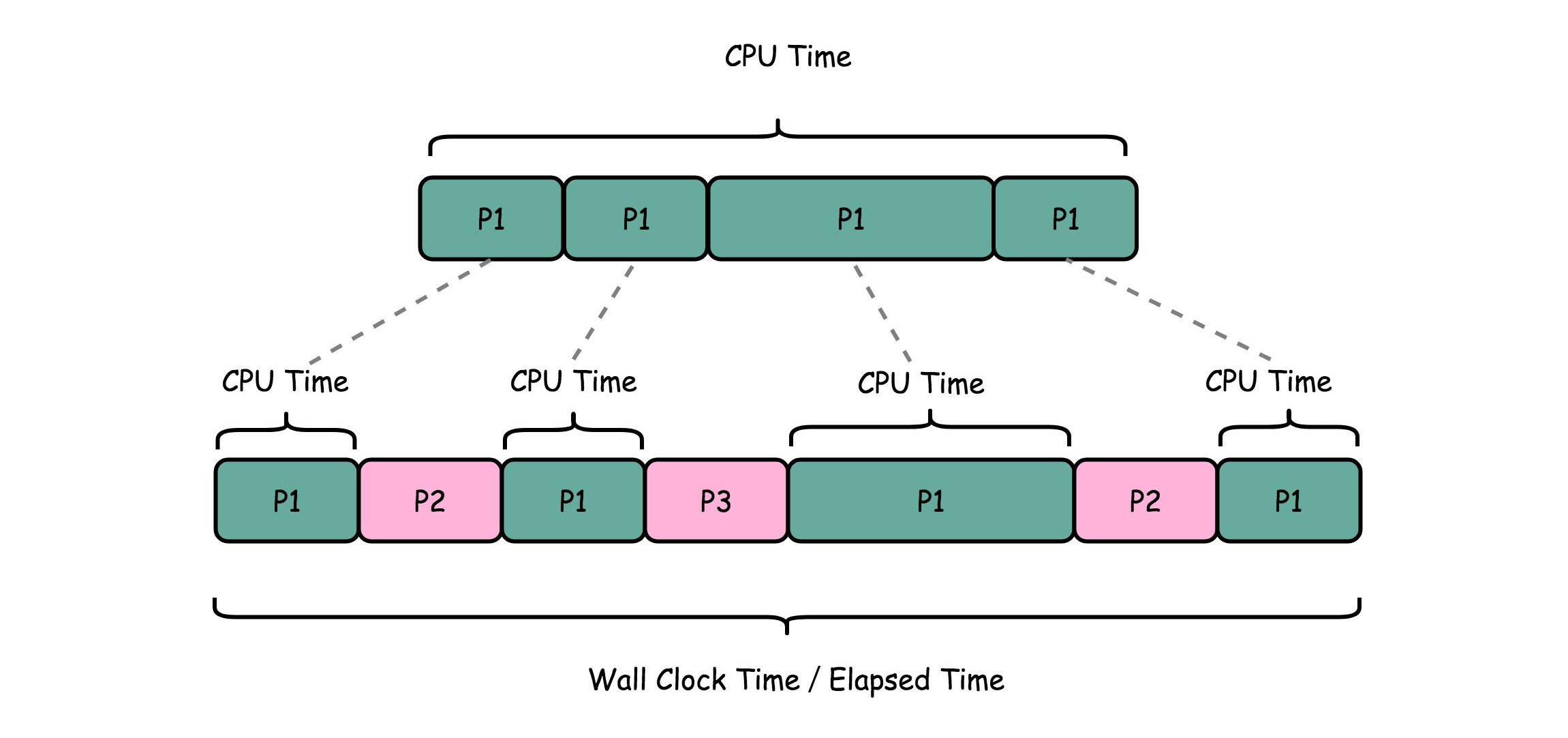
但是上面的现象也不是绝对的,比如在多核设备上,user和sys可能会同时执行,那最终的real可能就会小于user+sys
功耗
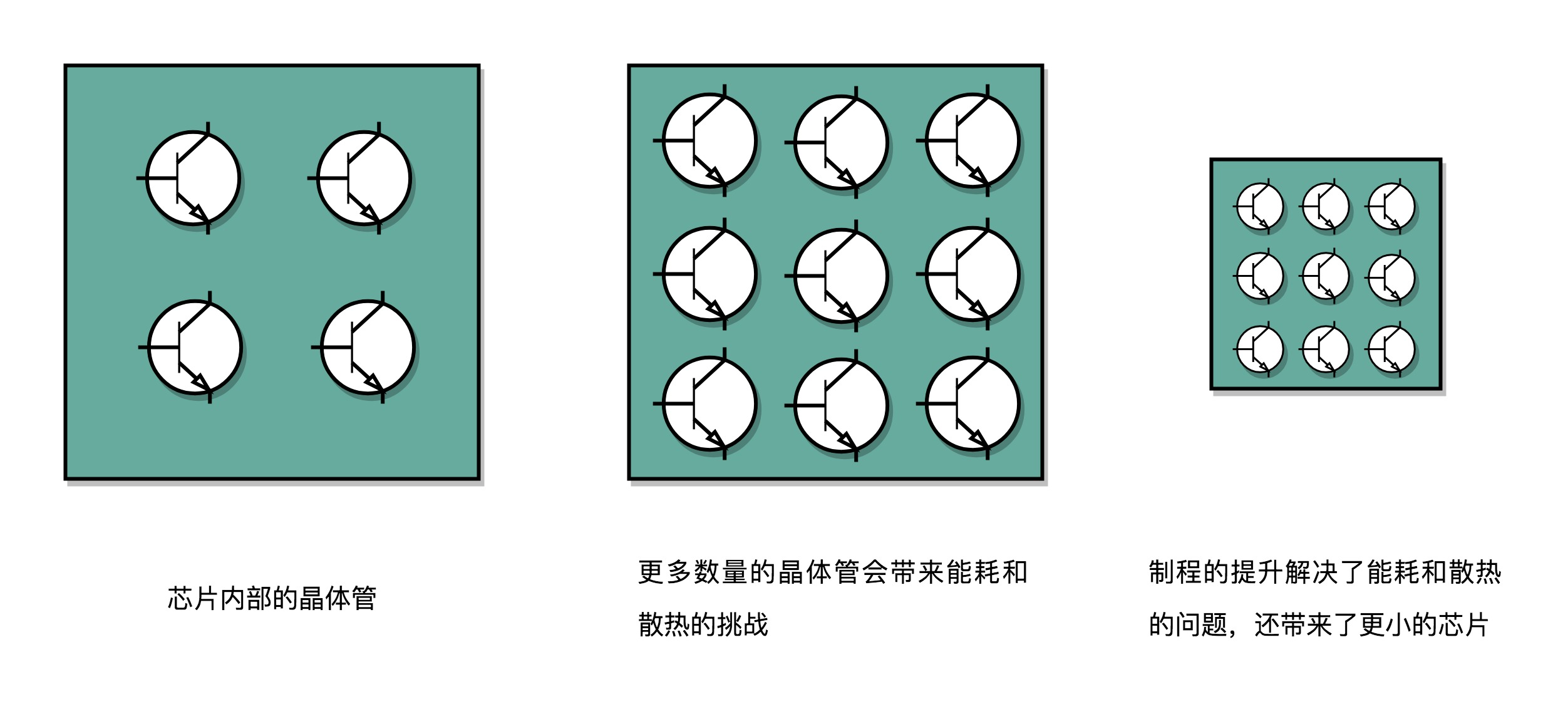
芯片本质上就是一个巨大的晶体管迷宫,通过控制开关来实现复杂运算。制程越短,晶体管的密度就越大,相应的性能就越好,但是由此可能会带来负面影响:晶体管散热不及时导致工作出错或者被干脆被烧毁,同时功耗也会增加,功耗的计算公式为:
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
其他提升性能的方式
既然晶体管数量提升有上限,那提升性能就只能在软件层面多优化了,主要是对CPI的优化,包括:
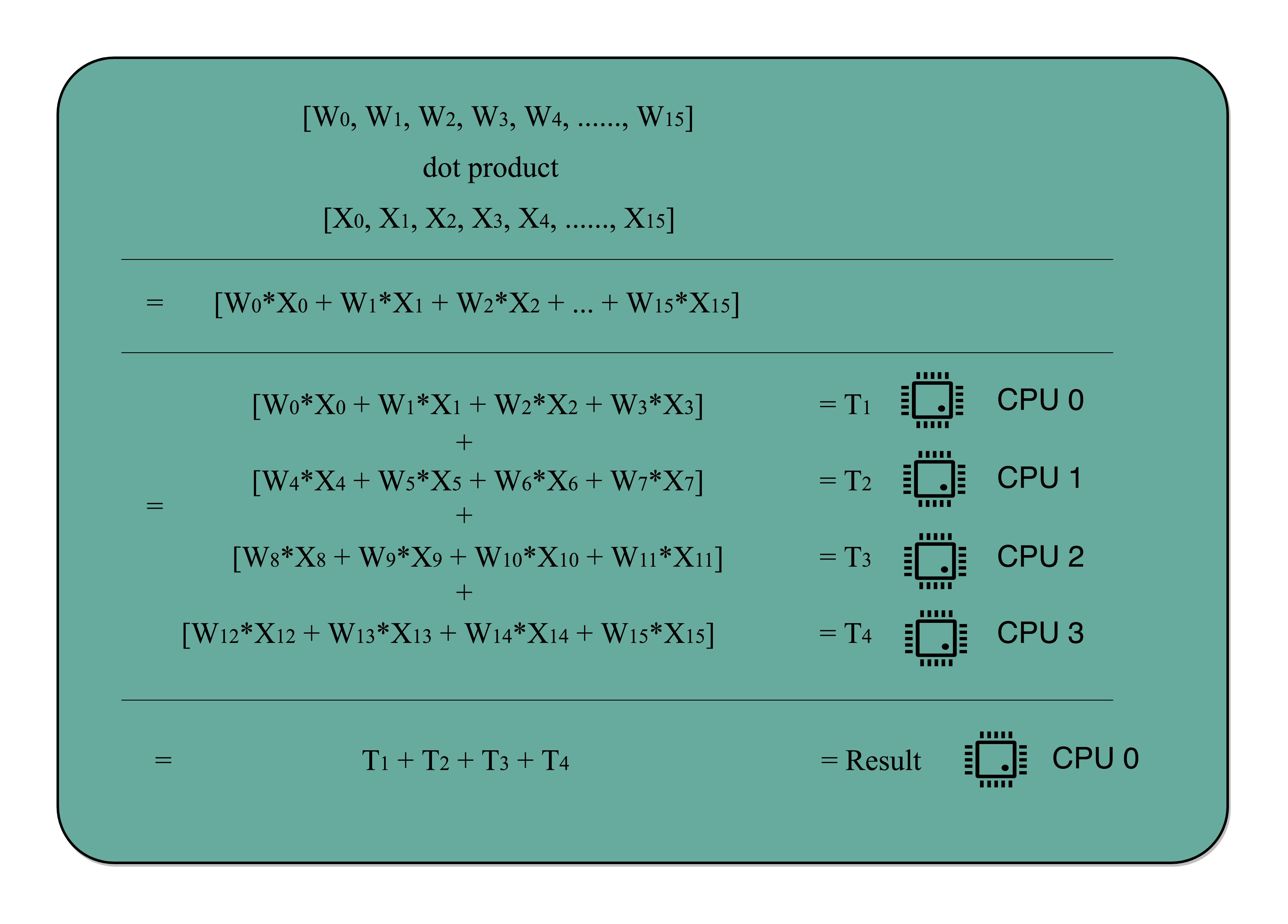
并行执行,核心思想就是分治,优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间(阿姆达尔定律),需要注意的是分治最后的汇总是不并行的,所以如果汇总时间长那优化的效果就会有限)
加快大概率事件,gpu性能比cpu好就是基于此
通过流水线提升性能,将执行的指令拆分然后并行执行
通过预测提升性能, 比如在条件语句执行前可以通过提前预测判断语句一定会执行,于是就可以提前运行语句代码从而加快执行速度